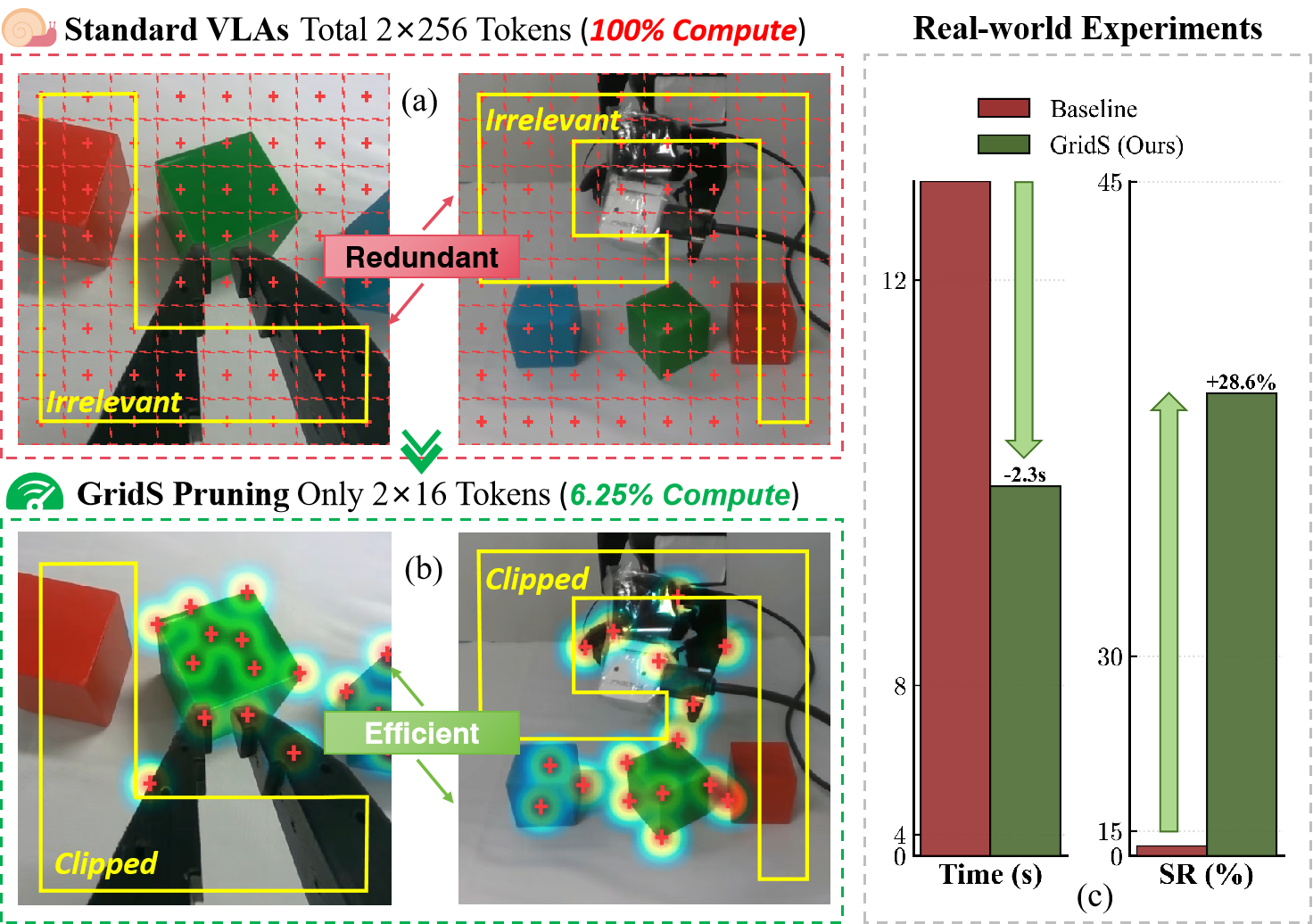
Grid Sampler
See What Matters: Differentiable Grid-Sample Pruning for Generalizable VLAs
1University of Sydney
2City University of Hong Kong
3StellarEdge Robotics
2City University of Hong Kong
3StellarEdge Robotics
ICML 2026
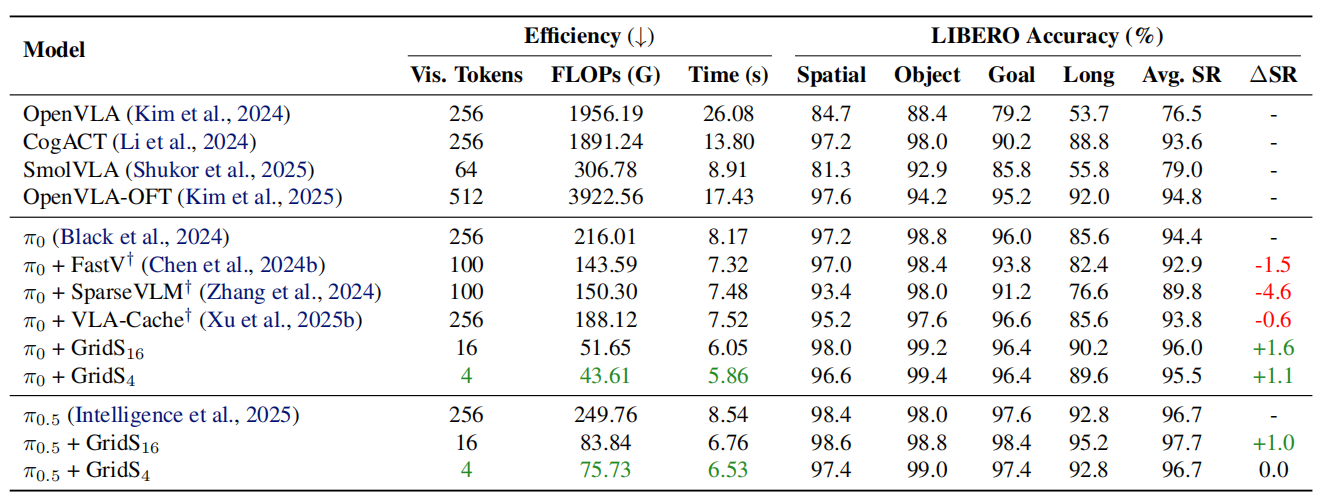
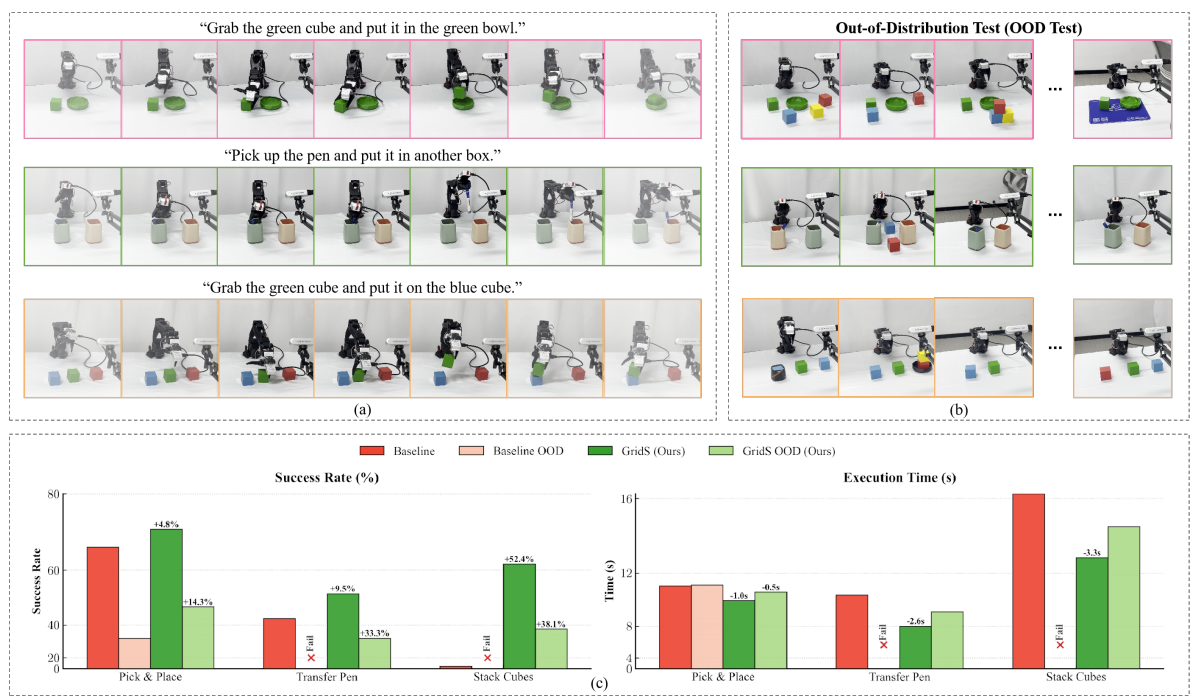
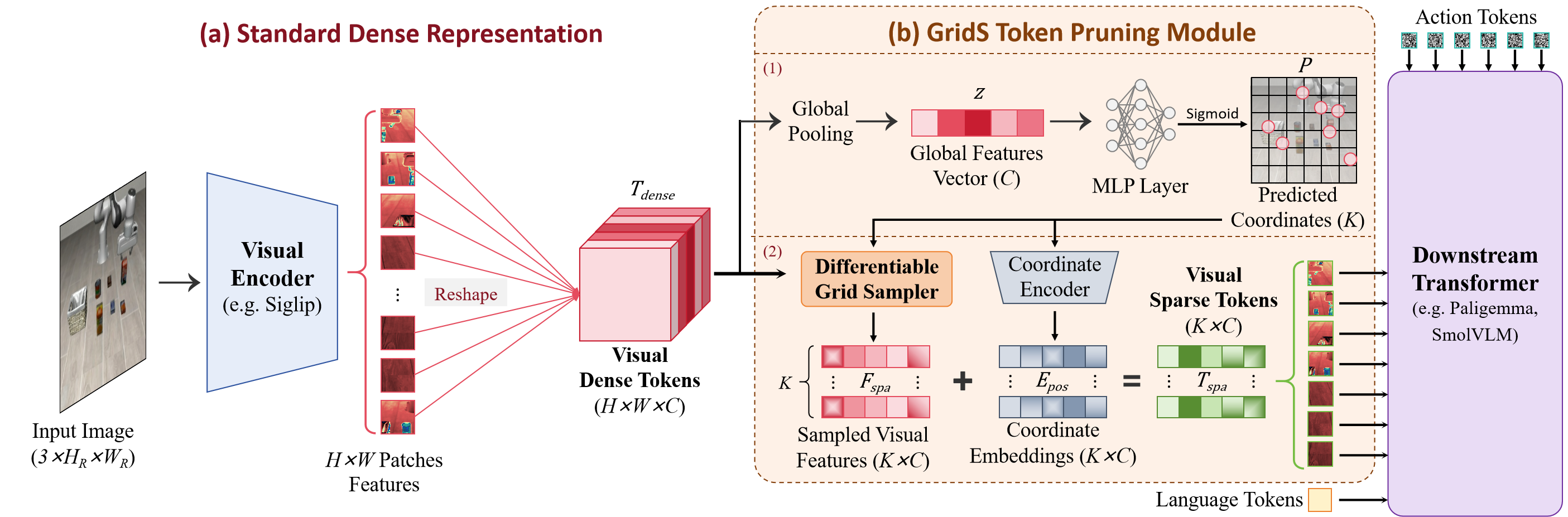
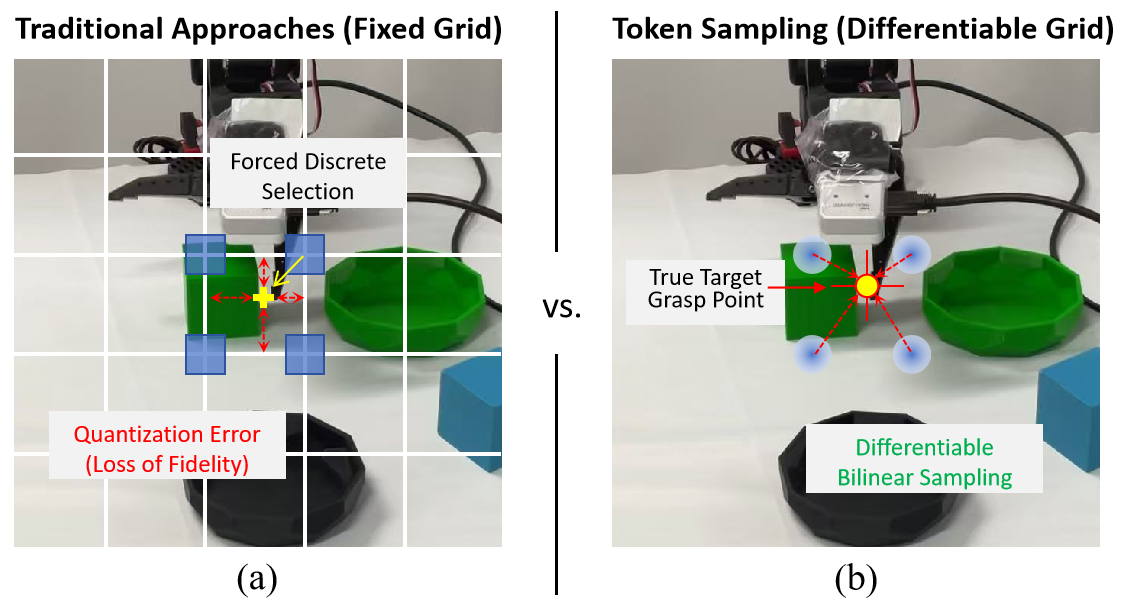
GridS uses only 1 visual token yet matches a 256-token dense baseline.